Toad DBA Suite로 패키징된 제품 중에서 먼저 TDM 제품에 대한 리뷰를 간략하게 작성해 보았다.
<먼저, 본 리뷰에서 언급한 사항 중에 툴에 대해서 깊이 있게 알지 못해서 혹은, 특정 기능을 찾지 못해서 잘못된 내용을 기술할 수도 있음을 미리 알린다. 나름 기능을 찾기 위해 매뉴얼도 찾아보고 했지만, 자료도 부족하고 영어 울렁증이 있어서 말이다.>
TDM은 데이터 모델링 툴이다. 대표적인 데이터 모델링 툴로는 국내에서 많이 사용하는 Allfusion ERWin, DA#(encore), ER/Studio(Embarcadero), PowerDesigner(Sybase), Visio(Microsoft) 등이 있으며 UML 툴에서 데이터모델링을 지원하거나 eclipse plug-in으로 나온 제품들도 있다.
예전에 TDM의 초기버전은 논리모델이 없었으며, 물리모델만을 모델링 할 수 있도록 구성되어 있었던 것으로 생각된다. 이번 버전은 기존의 기능에 논리모델 기능 및 여러가지 다양한 기능을 추가하여 나온 제품인 듯 하다.
<?xml:namespace prefix = o />
"百聞이 不如一見"
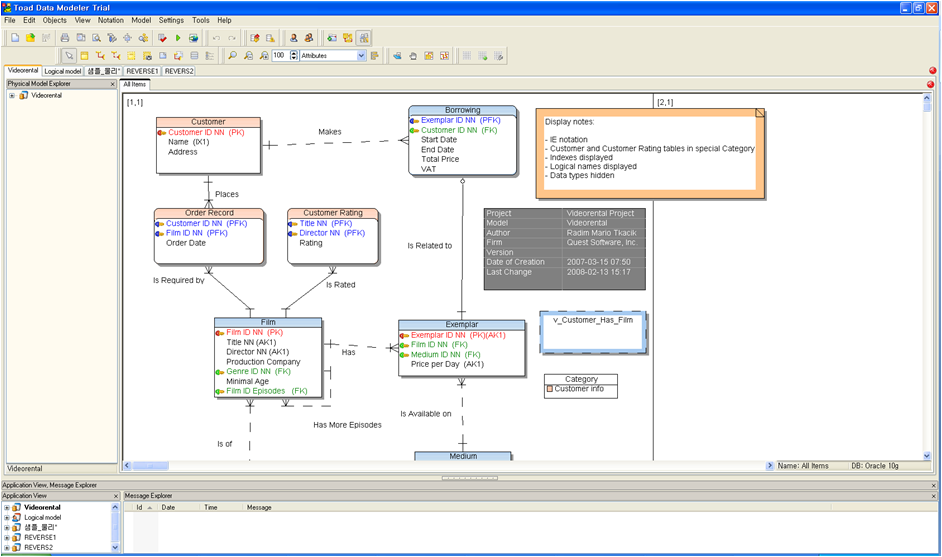
TDM을 설치 후에 처음으로 실행한 화면이다.
TDM이 TOAD만큼 유명한 제품이 아니라서 그런지 샘플모델을 디폴트로 로드되도록 구성되어 있다. 첫 느낌은 색깔이 화려한게 일단 맘에 든다.
LDM & PDM
TDM이 다른 모델링 툴과 가장 차이점은 LDM(Logical Data Model)과 PDM(Physical Data Model)을 작성하고 관리하는 방식인 것 같다.
대부분의 모델링 툴은 LDM과 PDM을 동일한 구조를 갖도록 구성해야 한다.
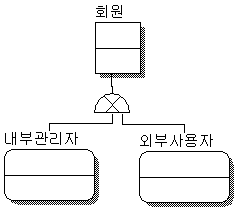
위의 그림과 같이 Super Type과 Sub Type으로 구성된 논리모델이 있을 때, 물리모델에서는 테이블 단위로 구성되기 때문에 물리모델 단계에서 각 엔티티를 하나의 엔티티로 통합하거나 각각의 서브타입으로 분리하거나 하는 방식으로 변경을 한다.
Erwin이나 대부분의 모델링 툴에서는 논리모델시에 위의 그림처럼 Subtype으로 모델링을 하여도 최종 물리모델단계로 넘어가면서 엔티티를 통합/분리하므로 최종적으로는 하나의 엔티티가 어떤 서브타입으로 구성되어 있는지 모델만 봐서는 파악하기가 어려워진다.(물론 별도의 파일로 작성하면 가능은 하지만 상당히 관리가 불편해진다.) 그런 단점이 있으나 논리모델과 물리모델이 동일한 모습을 가지게 되므로 논리모델에서 물리모델로 전환이 쉬워지는 장점이 있으며 하나의 파일로 관리된다는 점도 장점 중 하나이다.
그러나 TDM은 일반적인 하나의 파일로 논리/물리를 관리하지 않으며 별개의 파일로 논리/물리모델을 구성/관리하도록 되어 있다.
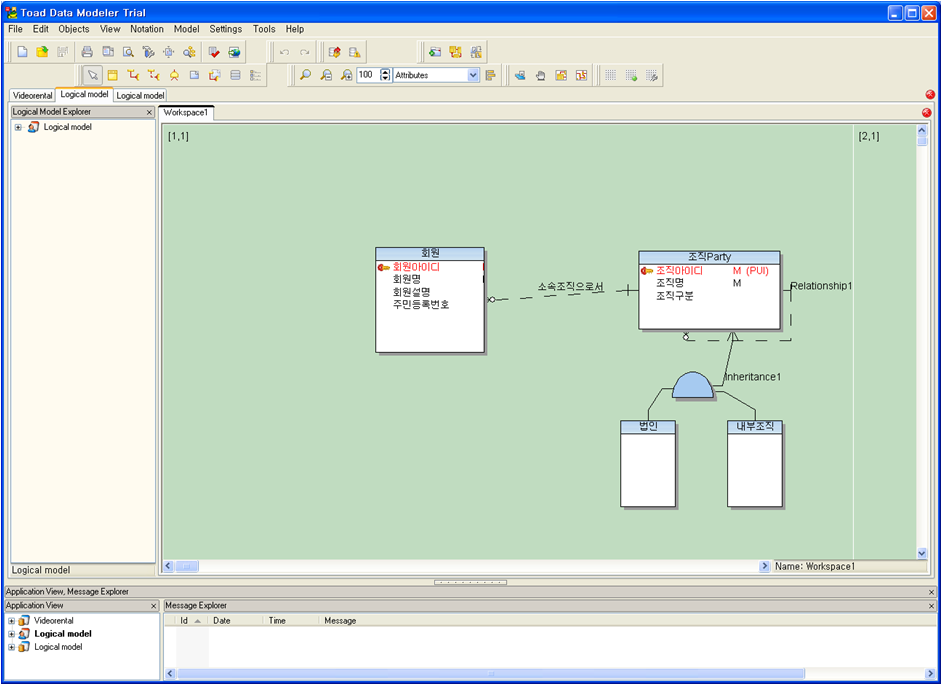
위의 그림과 같이 간단히 논리모델을 TDM으로 작성하였다. 물리모델을 작성하기 위해서는 TDM에서는 Convertor를 이용하여 물리모델을 생성하여야 한다.
다음은 툴의 기능을 이용하여 물리모델을 작성한 화면이다.
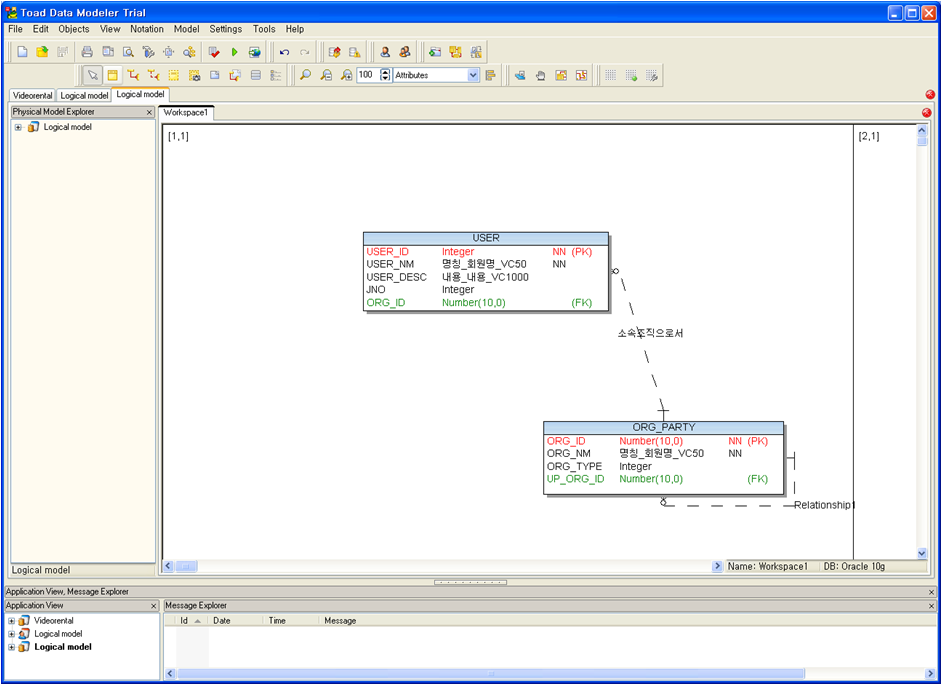
두 모델을 비교하면 물리모델에서는 Subtype이 하나의 테이블로 통합되어 구성이 되어있다. TDM에서는 이렇게 비즈니스 로직을 담고 있는 논리모델과 테이블구조를 가지는 물리모델을 분리하여 관리하도록 하여 논리모델에서는 비즈니스 로직만을 충실히 담을 수 있도록 구성하여 기존 툴과의 차별성을 내세우고 있다.
그러나 데이터모델은 지속적으로 변경된다. TDM에서는 한번 변환한 모델간의 Alignment가 되지 않는다는 치명적인 단점이 있다.
가령 논리모델에서의 “사용자아이디”란 속성이 물리모델에서의 “USER_ID”란 컬럼으로 변경되어 있다는 정보를 툴이 인식을 하지 못한다. 그러므로 논리모델의 속성명이 변경되거나 컬럼사이즈가 변경, 컬럼의 추가 등의 변경이 발생하더라도 물리모델에서 인식을 하지 못하므로 개별적으로 두 모델을 따로 관리하여야 한다.
혹시 Convertor를 이용하면 되지 않을까? 열심히 궁리를 해보았지만 Convertor에서는 “사용자아이디”와 “USER_ID”가 완전히 서로 틀린 컬럼으로 인식하고 있어서 방법이 없었다.
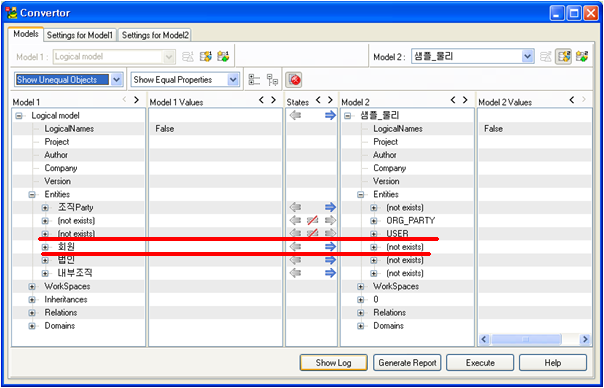
[위의 그림처럼 좌측의 회원이 물리모델에서 존재하지 않는 것으로 나타나며, 우측의 USER 테이블에 해당되는 좌측의 논리모델도 존재하지 않는 것으로 나타난다.]
매뉴얼을 찾아보니 모델 변경시에는 물리모델을 먼저 변경하고 변경사항을 역으로 PDM -> LDM으로 병합해야 한다고 나와있었다.
그 말은 비즈니스 모델이 변경되었지만 물리모델에서 먼저 작업하고 비즈니스 로직을 나중에 고치라는 말도 안되는 방식을 툴은 강요하고 있는 것이다.
차기 버전에서 가장 개선되어야 할 부분이 아닌가 싶다.
LDM과 PDM을 별도의 파일로 관리하는 모델링툴의 대표적인 사례는 DA#이 있다. 이 툴은 논리모델의 변경사항을 한번의 클릭으로 물리모델에서 정확히 인식하며 엔티티 레벨, 속성 레벨의 변경정보를 정확히 모델러에게 알려준다.
엔티티 속성 편집창
다음은 LDM의 엔티티 속성 편집창의 모습이다.
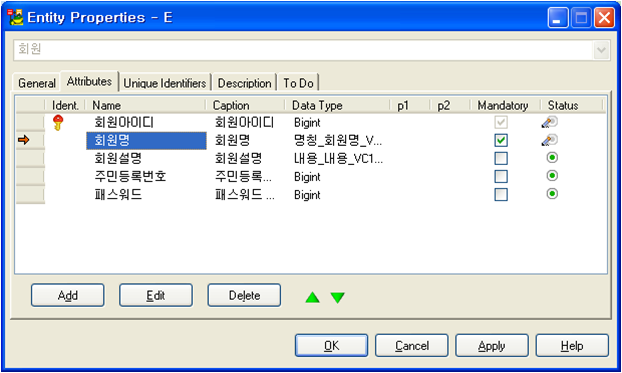
일반적인 엔티티의 속성 정보를 저장할 수 있는 UI이다.
Caption 항목은 속성의 설명정보를 담는 항목이다. 대부분의 툴에서는 Description 이름으로 제공하고 있다.
모델링을 하다 보면 Caption 및 Description 기능이 모두 필요하다.
특히 우리나라 같이 비 영문 국가에서는 테이블 생성시에 Comment 객체에 컬럼의 한글명을 기입하고 논리모델에서는 컬럼의 상세한 업무규칙 및 컬럼의 정의를 할 수 있다면 가장 best 하지만 아쉽게도 그렇게 구별하여 지원하는 툴은 아직까지는 보지 못한 것 같다.(나만 필요하다고 느끼는 것인지도 모르겠다)
컬럼편집
TDM에서는 컬럼별로 복사를 할 방법이 없다. 엔티티 레벨에서는 복사가 가능하나 LDM에서 특정 속성만을 선택하여 다른 엔티티로 컬럼을 복사할 방법이 없다. 등록일자/수정일자 같은 시스템 공통속성을 전 엔티티에 모두 두기 위해서는 각 엔티티마다 모두 입력하는 방법밖에 없다. 이 부분도 반드시 차기 버전에는 들어가야 될 기능이 아닐까 싶다.
데이터 표준화 지원
TDM의 또 다른 단점 중 하나는 데이터 표준화에 대한 지원이다.
TDM에서 도메인을 지원하기는 하나 계층적으로 구성할 수가 없고 별도의 도메인타입을 만들 수 가 없어서 모든 도메인을 1차원적으로 구성해야 한다. 조금은 아쉬운 부분이다.
또한, 물리모델 생성시에 단어 및 용어 표준화를 지원하지 않는다. 툴을 열심히 뒤졌것만 찾을 수가 없었다. 특히 우리나라같이 한글로 논리모델을 작성하고 영문컬럼명으로 물리모델을 변환해서 사용해야 하는 환경에서 영문컬럼명 변환을 매번 모든 컬럼을 클릭하여 입력한다는 것은 엄청난 노가다다. 용어사전을 생성하여 두고 자동으로 변환되지 않는다면 엔티티가 100개만 넘어가더라도..(생각하기도 싫다)
이 부분도 차기 버전에 반드시 들어가야 될 기능이 아닌가 싶다.
WorkSpace & UI
TDM에서는 주제영역(Subject Area)를 Workspace란 명칭으로 사용한다. eclipse의 영향인 것 같기도 하다. 거의 모든 툴에서 subject area란 용어를 사용하는데 말이다.
TDM의 편리한 점 중 하나는 여러 모델을 tab 방식으로 조회를 할 수 있는 점인 것 같다.
그리고 TDM에서는 실행취소 기능을 제공한다. 이게 얼마나 편리한 기능인지는 이 기능이 없는 툴을 사용해 본 사람이면 공감을 할 것이다. Erwin의 경우에도 아직도 많은 사람들이 사용하고 있는 v4.xxx 버전에서는 이 기능이 없다. r7 버전부터 이 기능을 제공하고 있으니 말이다. 엔코아의 모델링 툴인 da# 의 경우도 실행취소 기능이 없어서 어떤 땐 무지 짜증이 날 때도 있다. TDM에서는 이 기능을 제공해 주니 그래도 쓸만은 하다.
Reverse Engineering
리버스 엔지니어링은 초기 AS-IS 데이터 모델 분석시에 반드시 필요한 부분이다. 특히 엔티티가 몇 백개씩 되는 대형 사이트에서는 이 기능이 없으면 DB 분석시에 엄청난 시간이 걸릴것이다. 리버스 엔지니어링과 관련하여 또 반드시 필요한 기능은 테이블 정렬 기능이다. 몇 백개 되는 테이블이 아무런 연관없이 이름을 툴위에 쭉 나열한다면 테이블을 거의 분석하기가 힘들것이다. 대부분의 시스템에서 명식적인 FK를 설정하지 않고 데이터베이스를 구성하기 때문에 툴에서 컬럼명을 기준으로 가상의 Relation을 생성해주고, 사용자가 지정하는 Key Entity 혹은 Main Entity를 중심으로 주변에 Action Entity를 배치하게 해준다면 리버스 된 모델이 사용자가 인지하기 쉬운 구조로 재배치되어 많은 도움이 되리라 생각된다.
TDM에서는 리버스 기능은 훌륭하나 테이블 정렬기능은 단순정렬밖에 제공되고 있지 않아 아쉬움이 남는다.
아래 그림은 운영하고 있는 시스템을 리버스로 물리모델을 생성하는 과정을 담고 있는 화면이다.
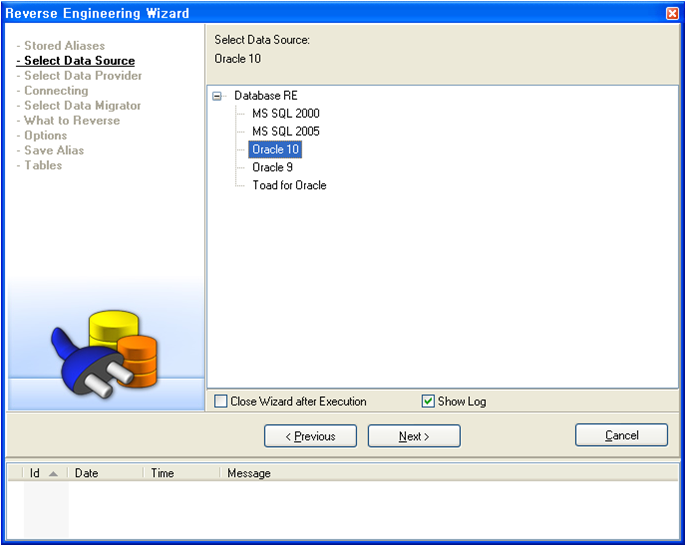
설치시에 데이터소스를 오라클과 MS-SQL만으로 한정하였기에 해당되는 항목이 위의 정보만 나타난다. MS-SQL 2008과 ORACLE11도 출시되었으니 조만간에 추가되지 않을까 싶다. 또한 QUEST사의 대표적인 제품인 TOAD와 연동할 수 있는 기능이 눈에 띈다.
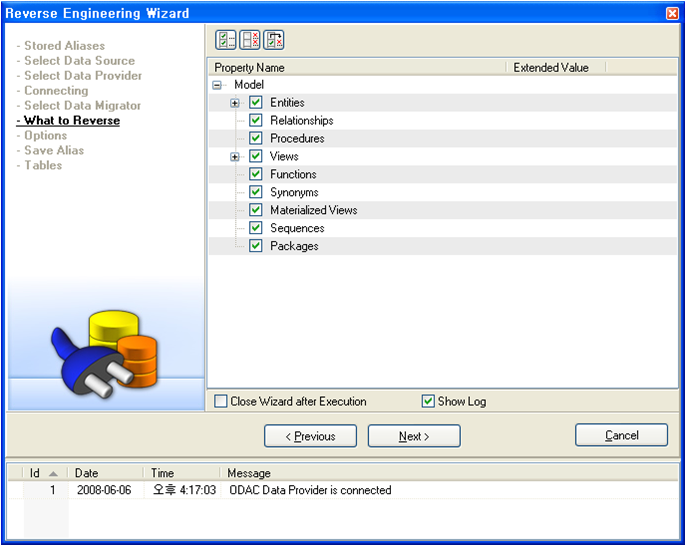
Data Provider 및 접속정보를 입력한 후 Reverse해야 될 대상을 선택하는 화면이다.
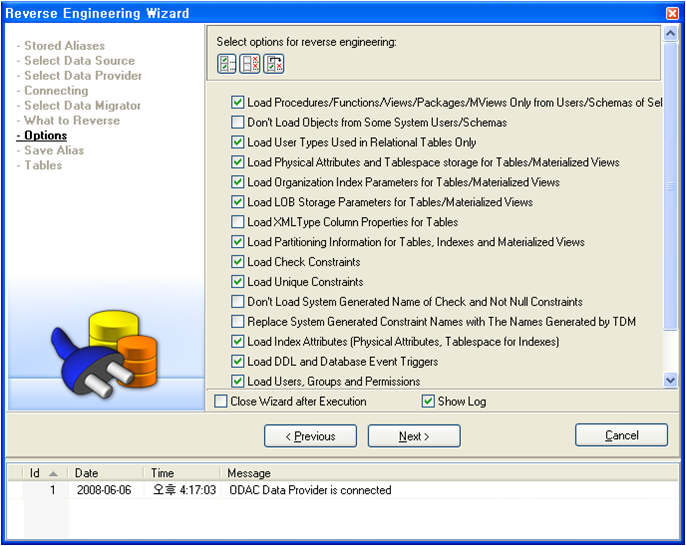
다음은 리버스에 대한 옵션을 선택하는 화면이다.
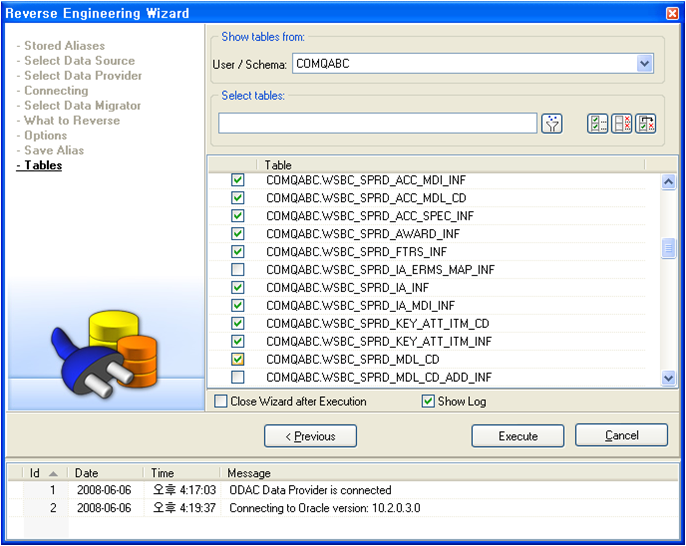
최종적으로 리버스해야될 테이블은 선택하고 나서 Execute 버튼을 클릭하면 TDM은 리버스를 시작한다.
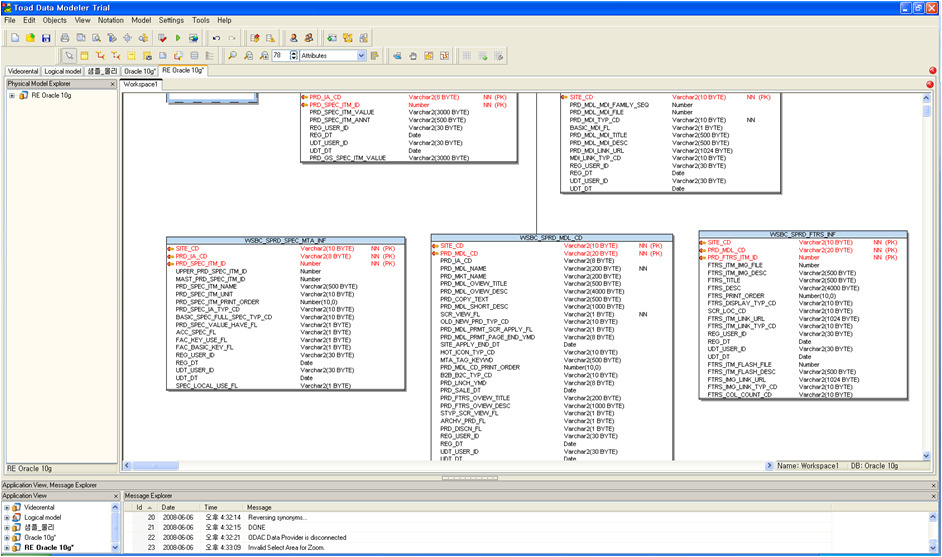
위의 그림은 최종적으로 리버스된 물리모델의 모습이다.
테이블 속성편집 창
리버스된 테이블의 속성 편집창이다.
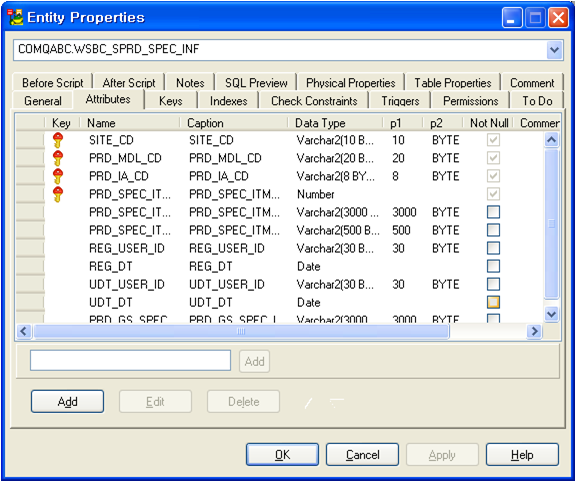
상당히 많은 탭이 보인다.
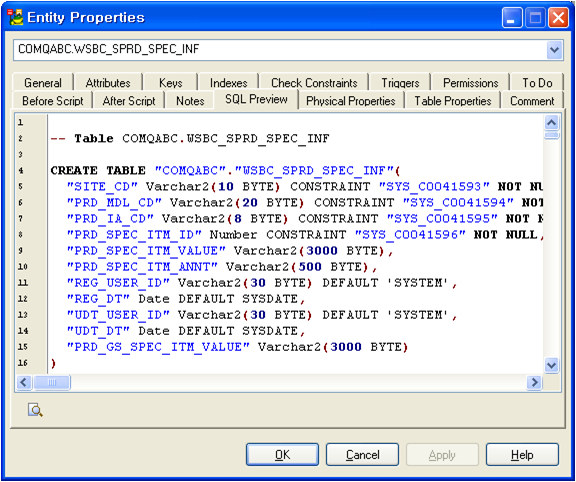
SQL Preview 기능은 다른 툴에서는 잘 없는 기능인데 편리한 기능인 것 같다.
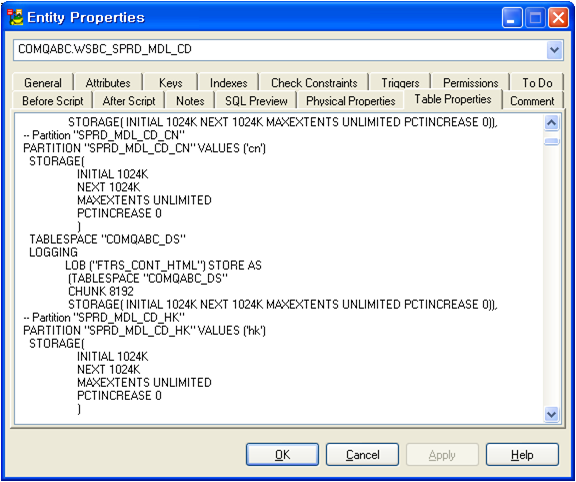
테이블의 속성정보 (위 그림은 파티션정보이다.)을 콤보박스나 그리드 같은 UI를 사용하지 않고 Text로 입력하도록 구성되어 있는 모습이다.
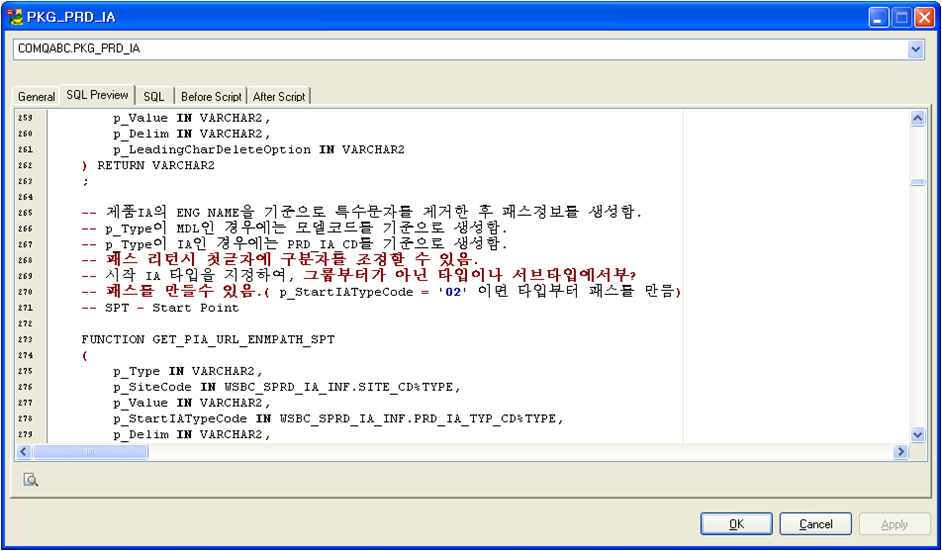
리버스한 정보 중 오라클 패키지의 SQL Preview화면이다. 주석의 일부분이 진한갈색으로 보이는건 왜 그런지 모르지만 리버스는 훌륭히 수행한 것 같다.
모델 Compare 및 Alter Script Generation
극히 일부의 모델링툴에서만 제공하는(Erwin) 편리한 기능이 TDM에도 탑재되어 있다. 모델간의 비교 및 비교를 통한 Alter Script를 생성해주는 기능이다. 변경되는 양이 적을 경우에는 툴보다는 손으로 스크립트를 작성하는게 편리하다. 그러나 큰 규모의 변경이 일어나는 경우에는 툴의 기능을 이용하면 편리하게 업무를 처리할 수 있다.
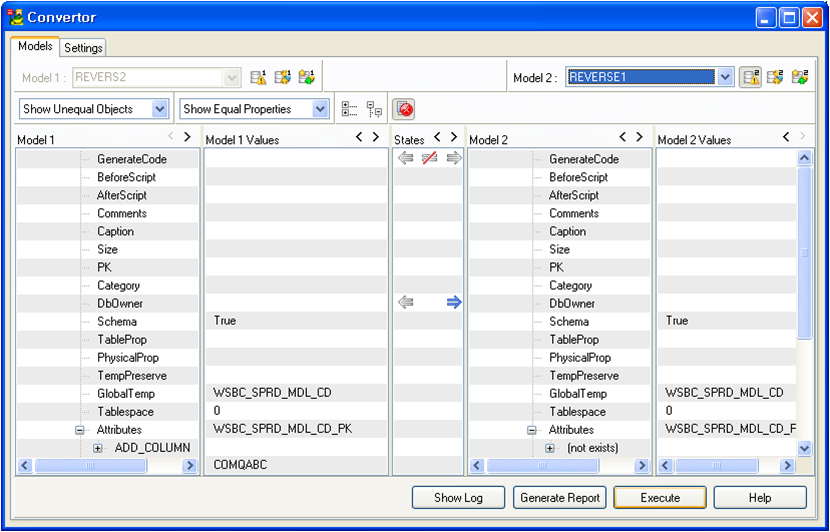
위의 그림은 물리모델에서 하나의 컬럼을 추가한 후 ALTER SCRIPT를 생성하기 위해 Convertor를 실행시킨 모습이다.
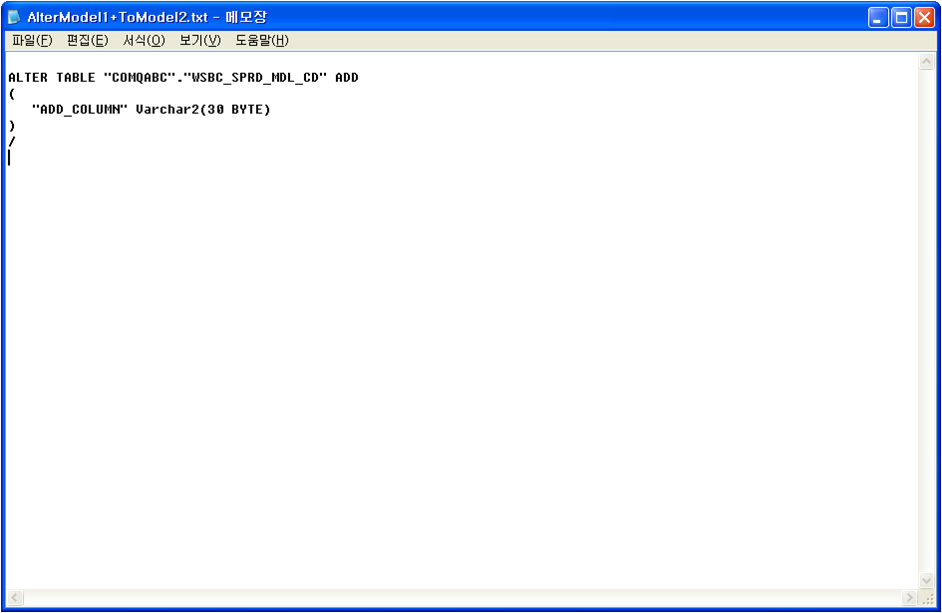
최종적으로 생성된 Alter 스크립트이다. 변경된 부분 중에서 필요한 부분만 선택하여서 Alter 스크립트를 생성할 수 있다.
Reporting
프로젝트 개발시에 모델링에 대한 산출물은 필수산출물이다. 나는 대체로 별도로 산출물을 작성하지 않으며 ER모델을 아주 상세하게 작성한 후 고객사의 양식에 맞게끔 툴로 Generation하여 제출하는 편이다. 그러므로 이 기능은 아주 필요한 기능이다.
TDM은 HTML 방식과 rtf 파일을 제공하고 있다.
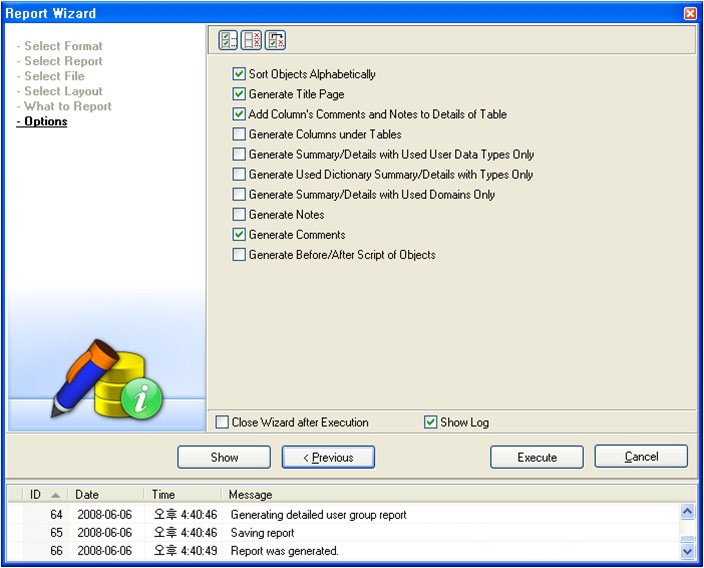
위의 그림은 Report 생성시에 필요한 사항을 선택하는 화면이다.
최종적으로 Reporting된 화면은 아래와 같다
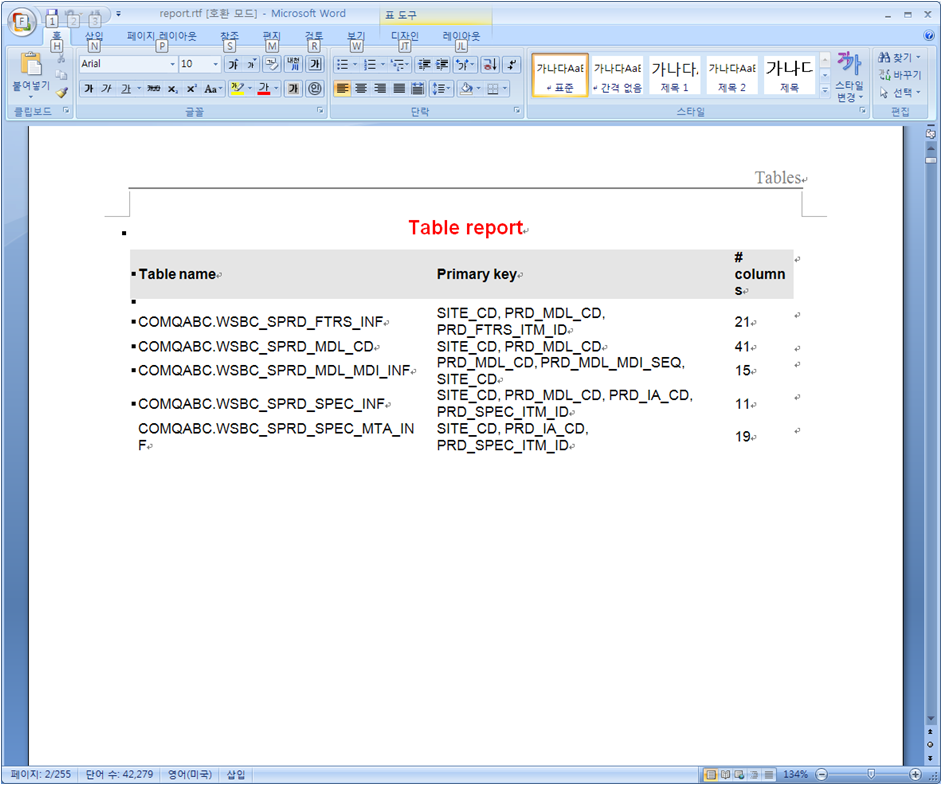
내부 프로젝트나 별도의 양식이 없는 프로젝트의 경우에는 사용이 가능하나 고객사 혹은 내부 산출물 양식이 지정되어 있는 경우는 이정도 레포팅 기능으로는 부족하지 않나 싶다.
별도의 양식을 디자인하는 기능이나 혹은 Erwin처럼 별도의 API를 제공은 고사하더라도 최소한 엔티티나 테이블의 정보를 엑셀로 출력하는 기능정도는 있어야 하지 않을까 싶다.
총평
Toad Data Modeler(TDM)은 버전 3으로 오면서 많은 기능이 추가되었지만, 아직까지는 부족한 기능이 많은 편이다. 소규모 프로젝트에서는 가능한 수준이 아닌가 싶다. 그러나 데이터베이스 관련한 SW의 노하우가 많은 Quest사의 제품이니만큼 그리 오래지 않아 필요한 기능들이 모두 추가되고 TDM만이 제공하는 특별한 기능까지. 향후에는 Toad와 같은 명성을 TDM도 얻을 수 있으리라 생각한다.
'삽질로그' 카테고리의 다른 글
| 가격제안에 사용하는 계정과목표준 (0) | 2009.05.10 |
|---|---|
| 나만의 UCC 사이트 구축하기 (0) | 2008.12.26 |
| 데이터모델링 (0) | 2008.11.28 |
| 자바스크립트로 UI 구현하기 (0) | 2008.10.11 |
| 검색의 혁명 Search 2.0 (0) | 2008.09.24 |







 MSAppLocale.msi
MSAppLocale.msi 체리마스터.zip
체리마스터.zip 산출물관리지침.pdf
산출물관리지침.pdf




